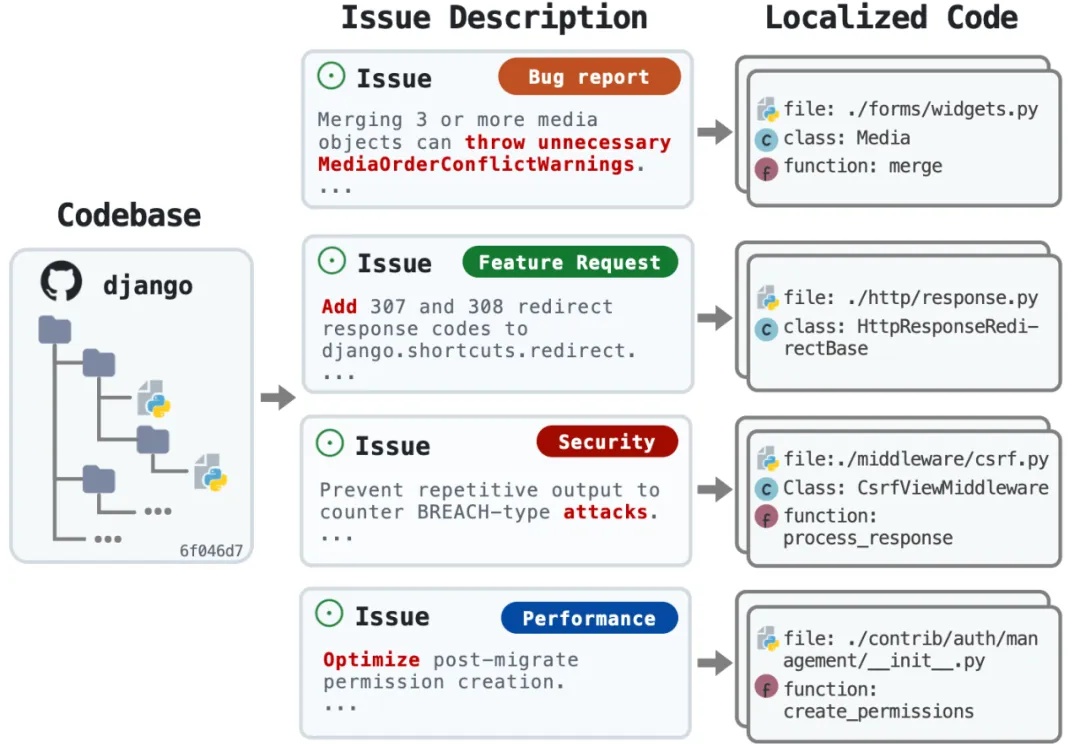
MetaMind元认知多智能体,让LLM理解对话背后的深层意图,首次达到人类水平 | 最新
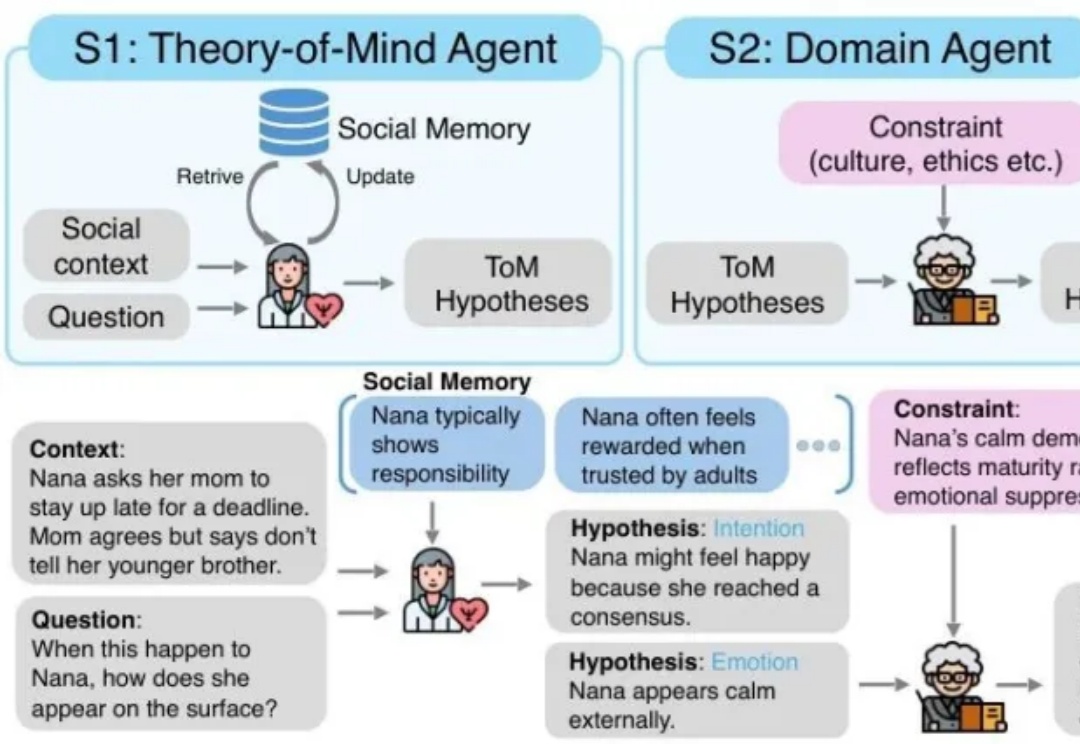
MetaMind元认知多智能体,让LLM理解对话背后的深层意图,首次达到人类水平 | 最新MetaMind是一个多智能体框架,专门解决大语言模型在社交认知方面的根本缺陷。传统的 LLM 常常难以应对现实世界中人际沟通中固有的模糊性和间接性,无法理解未说出口的意图、隐含的情绪或文化敏感线索。MetaMind首次使LLMs在关键心理理论(ToM)任务上达到人类水平表现。
来自主题: AI技术研报
11638 点击 2025-05-29 10:31